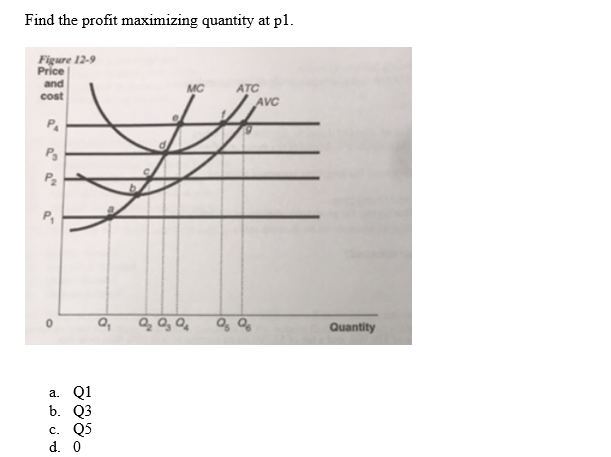
The Quantity Q3 Q1 Is Known As The
Understanding the distribution of data is fundamental to statistics. Several measures exist to describe the central tendency, spread, and shape of datasets. Among these, the quartiles play a critical role in summarizing the distribution. Specifically, the difference between the third quartile (Q3) and the first quartile (Q1) is a particularly useful measure known as the Interquartile Range (IQR).
What are Quartiles?
Before delving into the Interquartile Range, it's essential to understand what quartiles are. Quartiles divide a dataset into four equal parts when the data is arranged in ascending order. There are three quartiles:
- Q1 (First Quartile): Also known as the 25th percentile, it separates the bottom 25% of the data from the top 75%.
- Q2 (Second Quartile): This is the median of the dataset. It separates the bottom 50% from the top 50%. It's also the 50th percentile.
- Q3 (Third Quartile): Also known as the 75th percentile, it separates the bottom 75% of the data from the top 25%.
To find the quartiles, the data must first be sorted. Then, the median (Q2) is found. Q1 is the median of the lower half of the data (excluding the overall median if the dataset has an odd number of data points), and Q3 is the median of the upper half of the data (excluding the overall median if the dataset has an odd number of data points).
Must Read
For example, consider the following dataset: 3, 7, 8, 5, 12, 14, 21, 13, 18, 15, 20, 23.
First, we sort the data: 3, 5, 7, 8, 12, 13, 14, 15, 18, 20, 21, 23.
Next, we find the median (Q2): Since there are 12 data points, the median is the average of the 6th and 7th values: (13 + 14) / 2 = 13.5.
+and+the+first+quartile+(Q1)..jpg)
Then, we find Q1: The lower half of the data is 3, 5, 7, 8, 12, 13. The median of this is the average of the 3rd and 4th values: (7 + 8) / 2 = 7.5.
Finally, we find Q3: The upper half of the data is 14, 15, 18, 20, 21, 23. The median of this is the average of the 3rd and 4th values: (18 + 20) / 2 = 19.
The Interquartile Range (IQR)
The Interquartile Range (IQR) is calculated as the difference between the third quartile (Q3) and the first quartile (Q1):
IQR = Q3 - Q1
In the example above, the IQR would be 19 - 7.5 = 11.5.
.jpg)
The IQR represents the range containing the middle 50% of the data. It provides a measure of the spread or variability of the data around the median. A larger IQR indicates greater variability, while a smaller IQR indicates less variability.
Advantages of Using the IQR
The IQR has several advantages over other measures of spread, such as the range or standard deviation:
- Robustness to Outliers: The IQR is resistant to the influence of outliers. Since it only considers the middle 50% of the data, extreme values do not significantly affect its value. The range, on the other hand, is highly sensitive to outliers, as it is based on the maximum and minimum values.
- Ease of Interpretation: The IQR is straightforward to interpret. It simply represents the spread of the middle half of the data.
- Useful for Comparing Distributions: The IQR can be used to compare the spread of two or more distributions, even if they have different medians.
Using the IQR to Detect Outliers
The IQR is often used to identify potential outliers in a dataset. A common rule for outlier detection is based on the following:
-.jpg)
- Lower Bound: Q1 - 1.5 * IQR
- Upper Bound: Q3 + 1.5 * IQR
Any data point falling below the lower bound or above the upper bound is considered a potential outlier.
In our example, the IQR is 11.5, Q1 is 7.5, and Q3 is 19. Therefore:
- Lower Bound: 7.5 - 1.5 * 11.5 = 7.5 - 17.25 = -9.75
- Upper Bound: 19 + 1.5 * 11.5 = 19 + 17.25 = 36.25
In the dataset 3, 5, 7, 8, 12, 13, 14, 15, 18, 20, 21, 23, none of the values fall below -9.75 or above 36.25. Therefore, according to this rule, there are no outliers in this particular dataset.
Applications of the Interquartile Range
The Interquartile Range finds applications in various fields:
.jpg)
- Descriptive Statistics: The IQR is used as a descriptive statistic to summarize the spread of data.
- Box Plots: The IQR is a key component of box plots, a graphical representation of data that displays the minimum, first quartile, median, third quartile, and maximum values. Box plots are useful for comparing the distributions of different datasets. The "whiskers" in a box plot often extend to the farthest data point within 1.5 times the IQR from the quartiles, with points beyond that marked as outliers.
- Data Analysis: The IQR is used to identify outliers and assess the variability of data in various analytical contexts.
- Quality Control: In manufacturing and other industries, the IQR can be used to monitor the consistency of processes. A sudden increase in the IQR might indicate a problem with the process.
- Finance: The IQR can be used to analyze the volatility of financial instruments.
IQR vs. Standard Deviation
Both the IQR and the standard deviation are measures of data spread, but they differ in their sensitivity to outliers. The standard deviation is more sensitive to outliers than the IQR. This is because the standard deviation is calculated using all data points, while the IQR only considers the middle 50%.
When the data is normally distributed (or close to it), the standard deviation is often preferred because it provides a more complete picture of the data's spread. However, when the data contains outliers or is heavily skewed, the IQR is a more robust measure of spread. In such cases, the standard deviation can be misleading.
The choice between using the IQR and the standard deviation depends on the nature of the data and the goals of the analysis.
Conclusion
The Interquartile Range (IQR), calculated as the difference between the third quartile (Q3) and the first quartile (Q1), is a valuable measure of data spread. Its robustness to outliers makes it a particularly useful tool when dealing with datasets that may contain extreme values or that deviate significantly from a normal distribution. Understanding and utilizing the IQR allows for a more accurate and reliable assessment of data variability, leading to better informed decisions in various fields ranging from scientific research to business analytics. Its importance lies in providing a stable and easily interpretable metric for understanding how data is distributed, especially when dealing with potentially problematic datasets.