How To Lemmatize A Dataframe In Python

Ever feel like your data is speaking a different language? Like trying to understand your teenager after they've discovered a new slang word every single day? Yeah, data can be like that. You've got words in all sorts of forms - "running," "ran," "runs" - all basically meaning the same thing, but making your analysis a total headache. That's where lemmatization comes in, like a super-powered translator that brings everything back to its root.
Think of it as decluttering your digital closet. You've got a bunch of similar shirts - a t-shirt, a tank top, maybe even a long-sleeved version. Lemmatization is like saying, "Okay, all these are shirts! Let's just call them all 'shirt' for organizational purposes." It simplifies things, making it easier to see the big picture and get some real insights from your data.
What is Lemmatization, Anyway? (The Non-Boring Explanation)
Okay, let's get a little technical, but I promise to keep it painless. Lemmatization is the process of reducing words to their base or dictionary form, known as the lemma. Unlike stemming, which just chops off the ends of words (sometimes with hilarious results - imagine stemming "university" to "univers"! ), lemmatization actually understands the context and meaning of the word.
Must Read
It's like having a really smart dictionary that knows the difference between "is," "are," and "was," and can confidently tell you that they all boil down to "be." Stemming, on the other hand, might just hack off the "is" and leave you with... well, nothing useful.
So, why is this important? Because it allows you to group related words together, even if they appear in different forms in your dataset. This makes your analysis more accurate and efficient, especially when dealing with large amounts of text data. Think of it like trying to count the number of times someone mentions "dog" in a text. Without lemmatization, you'd have to count "dog," "dogs," "dog's," and maybe even "doggy" separately. With lemmatization, you just count "dog" once, and you're done!
Why Use Lemmatization Instead of Stemming?
Good question! Stemming is often faster and simpler than lemmatization, so why bother with the extra effort? Well, stemming can sometimes produce nonsense words or incorrect results, as we discussed earlier. It's like using a chainsaw to prune a delicate rose bush – you might get the job done quickly, but you're likely to cause some damage in the process.
Lemmatization, on the other hand, is more accurate and reliable. It takes into account the context and meaning of the word, so it's less likely to make mistakes. It's like having a skilled gardener who knows exactly how to prune each rose bush to encourage healthy growth.

However, lemmatization can be slower and more computationally expensive than stemming. So, the best approach depends on your specific needs and the size of your dataset. If you're working with a small dataset and need a quick and dirty solution, stemming might be sufficient. But if you're working with a large dataset and need accurate results, lemmatization is the way to go. Basically, choose your weapon based on the battle ahead!
Lemmatizing a Dataframe in Python: Let's Get Our Hands Dirty!
Alright, enough theory! Let's get into the fun part: actually lemmatizing a dataframe in Python. Don't worry, it's not as scary as it sounds. We'll use the NLTK (Natural Language Toolkit) library, which is like a Swiss Army knife for natural language processing.
First, you'll need to install NLTK. Open your terminal or command prompt and type:
pip install nltkOnce that's done, you'll need to download the necessary NLTK resources. Open a Python interpreter and type:
import nltk
nltk.download('wordnet')
nltk.download('averaged_perceptron_tagger')
This downloads the WordNet lexicon (a large lexical database of English) and the averaged perceptron tagger (used for part-of-speech tagging). Think of it as downloading the essential vocabulary and grammar rules for our data's language.
Step-by-Step Guide with Code Examples
Now, let's get to the code. We'll assume you have a dataframe with a column containing text data. Here's a basic example:
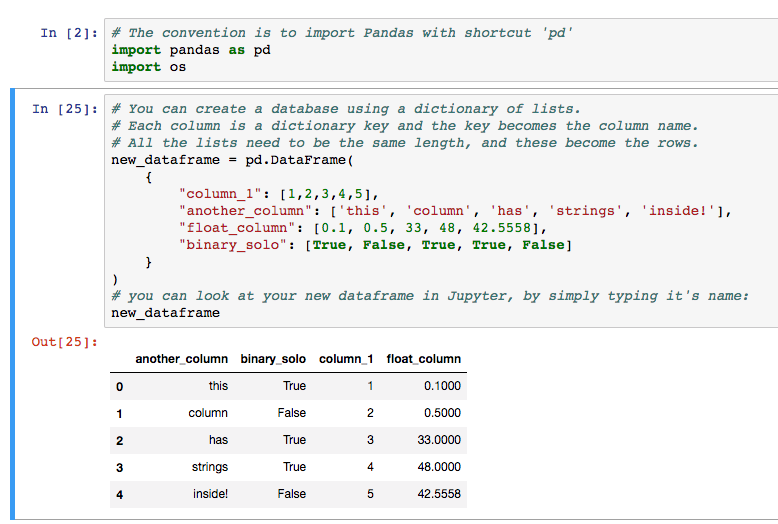
import pandas as pd
import nltk
from nltk.stem import WordNetLemmatizer
from nltk.corpus import wordnet
# Sample dataframe
data = {'text': ["The cats are running quickly.", "He was eating a delicious apple.", "They have been building houses."]}
df = pd.DataFrame(data)
print(df)
Next, we need to initialize the WordNetLemmatizer:
lemmatizer = WordNetLemmatizer()
Now, this is where it gets a little interesting. The lemmatizer needs to know the part of speech (POS) of each word to lemmatize it correctly. For example, "running" as a verb should be lemmatized to "run," but "running" as a noun (e.g., "the running of the bulls") should be lemmatized to "running."
NLTK provides a function called `pos_tag` that can help us with this. But the tags returned by `pos_tag` are slightly different from what WordNetLemmatizer expects. So, we need to create a helper function to convert the NLTK POS tags to WordNet POS tags:

def get_wordnet_pos(treebank_tag):
if treebank_tag.startswith('J'):
return wordnet.ADJ
elif treebank_tag.startswith('V'):
return wordnet.VERB
elif treebank_tag.startswith('N'):
return wordnet.NOUN
elif treebank_tag.startswith('R'):
return wordnet.ADV
else:
return wordnet.NOUN # Default to noun if unknown
This function maps common POS tags like adjectives ('J'), verbs ('V'), nouns ('N'), and adverbs ('R') to their corresponding WordNet equivalents. If the tag isn't recognized, it defaults to a noun.
Now, we can create a function to lemmatize a single sentence:
def lemmatize_sentence(text):
tokens = nltk.word_tokenize(text)
tagged = nltk.pos_tag(tokens)
lemmatized_words = [lemmatizer.lemmatize(word, get_wordnet_pos(tag)) for word, tag in tagged]
return " ".join(lemmatized_words)
This function first tokenizes the sentence into individual words using `nltk.word_tokenize`. Then, it tags each word with its part of speech using `nltk.pos_tag`. Finally, it lemmatizes each word using the `lemmatizer.lemmatize` function, passing in the word and its corresponding WordNet POS tag. It joins lemmatized words back to a string.
Finally, we can apply this function to the 'text' column of our dataframe:

df['lemmatized_text'] = df['text'].apply(lemmatize_sentence)
print(df)
And that's it! You should now have a new column in your dataframe called 'lemmatized_text' containing the lemmatized versions of your text data. Check the output!
Let's break down the code:
- `import pandas as pd`: Imports the Pandas library for data manipulation.
- `import nltk`: Imports the NLTK library for natural language processing.
- `from nltk.stem import WordNetLemmatizer`: Imports the WordNetLemmatizer class for lemmatization.
- `from nltk.corpus import wordnet`: Imports the wordnet corpus for POS tagging.
- `lemmatizer = WordNetLemmatizer()`: Creates an instance of the WordNetLemmatizer.
- `df['text'].apply(lemmatize_sentence)`: Applies the `lemmatize_sentence` function to each row in the 'text' column of the dataframe.
Tips and Tricks for Supercharged Lemmatization
Here are a few extra tips and tricks to make your lemmatization even more effective:
- Handle contractions: Before lemmatizing, expand contractions like "can't" to "cannot" and "won't" to "will not." This will ensure that the lemmatizer correctly identifies the root forms of these words. Libraries like `contractions` can help with this.
- Remove punctuation and stop words: Punctuation and stop words (like "the," "a," and "is") don't usually contribute much to the meaning of a text and can sometimes interfere with lemmatization. Remove them before lemmatizing to improve accuracy.
- Consider using a different lemmatizer: While WordNetLemmatizer is a good general-purpose lemmatizer, other lemmatizers like SpaCy's lemmatizer might be more suitable for specific tasks or datasets. SpaCy generally provides faster and more accurate results but has a larger footprint, meaning its models take up more space. Experiment to see what works best for you.
- Pre-process your data: Clean your data before lemmatizing. This may involve removing HTML tags, special characters, or other irrelevant information. The cleaner your data, the better the lemmatization results will be.
Real-World Applications: Where Lemmatization Shines
So, where can you actually use lemmatization in the real world? Here are a few examples:
- Sentiment analysis: Lemmatizing text can improve the accuracy of sentiment analysis by grouping together different forms of the same word. For example, "happy," "happier," and "happiest" would all be lemmatized to "happy," allowing you to accurately measure the overall sentiment expressed in a text.
- Text summarization: Lemmatization can help identify the key concepts and themes in a text, making it easier to generate accurate and concise summaries.
- Chatbots and virtual assistants: Lemmatization can help chatbots understand user queries more accurately, even if they contain misspellings or grammatical errors.
- Information retrieval: Lemmatization can improve the accuracy of search engines by matching search queries with relevant documents, even if the documents contain different forms of the same words.
- Topic modeling: Lemmatizing words allows to group similar words together which enables better and more accurate topic modelling.
Conclusion: Taming Your Text Data, One Lemma at a Time
Lemmatization is a powerful tool that can help you make sense of your text data. It's like having a magic wand that can transform messy, unorganized text into clean, structured information. By understanding the basics of lemmatization and how to implement it in Python, you can unlock new insights and gain a deeper understanding of your data. It's not always a walk in the park, but with a little practice, you'll be lemmatizing like a pro in no time! So go forth, and lemmatize! Your data will thank you for it. Happy analyzing!