How To Find Height Of Density Curve
Hey there, data enthusiast! Ever stared at a density curve and wondered, "How tall is that thing, anyway?" It's a legitimate question! We're diving into the quirky world of density curves, and specifically, how to find their height. Buckle up – it's more fun than it sounds, promise!
What's the Deal with Density Curves?
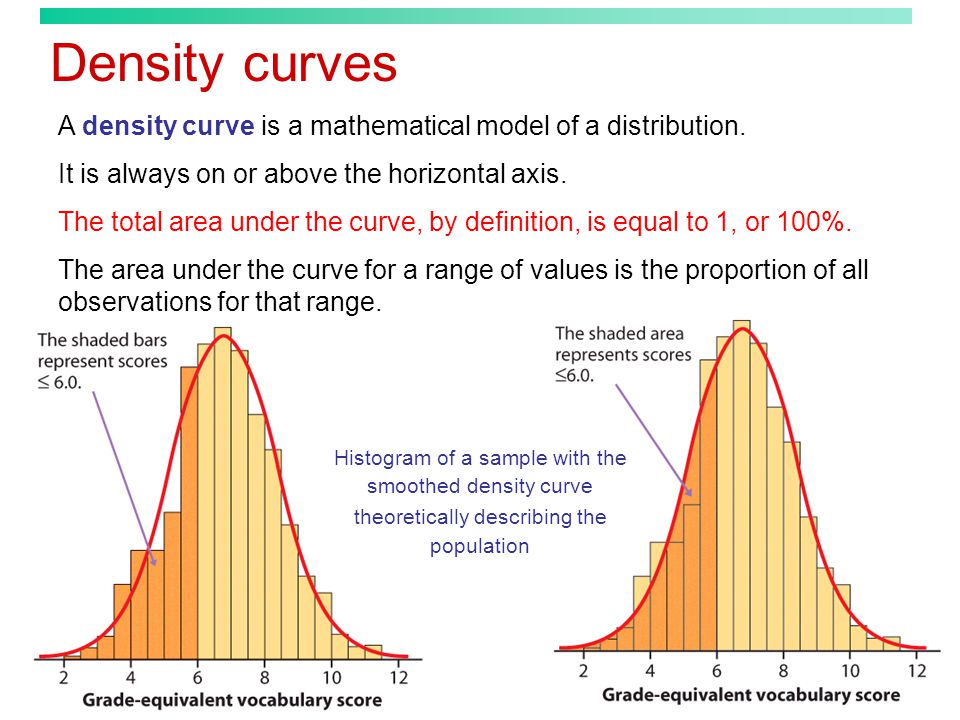
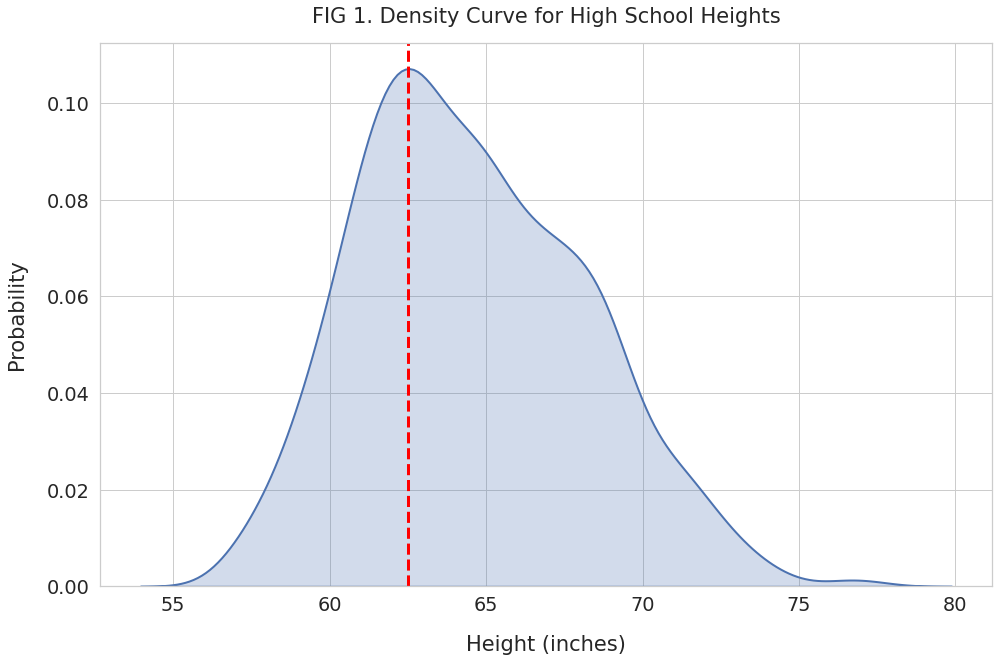
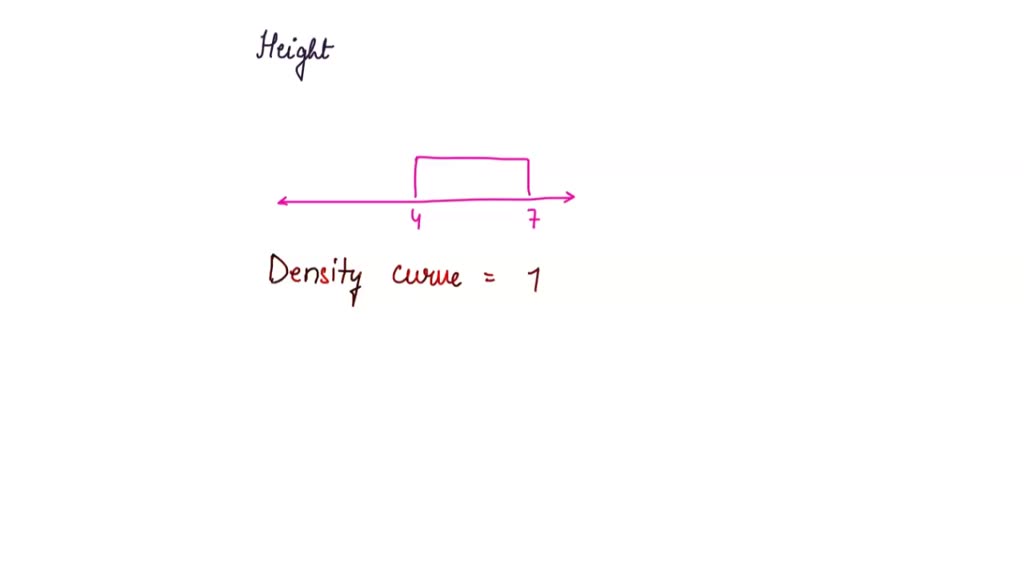
Okay, picture this: you've got a bunch of data. Like, a lot. Maybe it's heights of people, weights of cats, or the number of jellybeans in a jar. A density curve is basically a smooth, continuous representation of that data. Think of it like a silhouette of a histogram – a smoothed-out version that shows you the distribution of your data.
Density curves are cool because they give you a visual snapshot of where your data is clustered. They show you the most common values (the peak of the curve!) and how spread out everything is.
Must Read
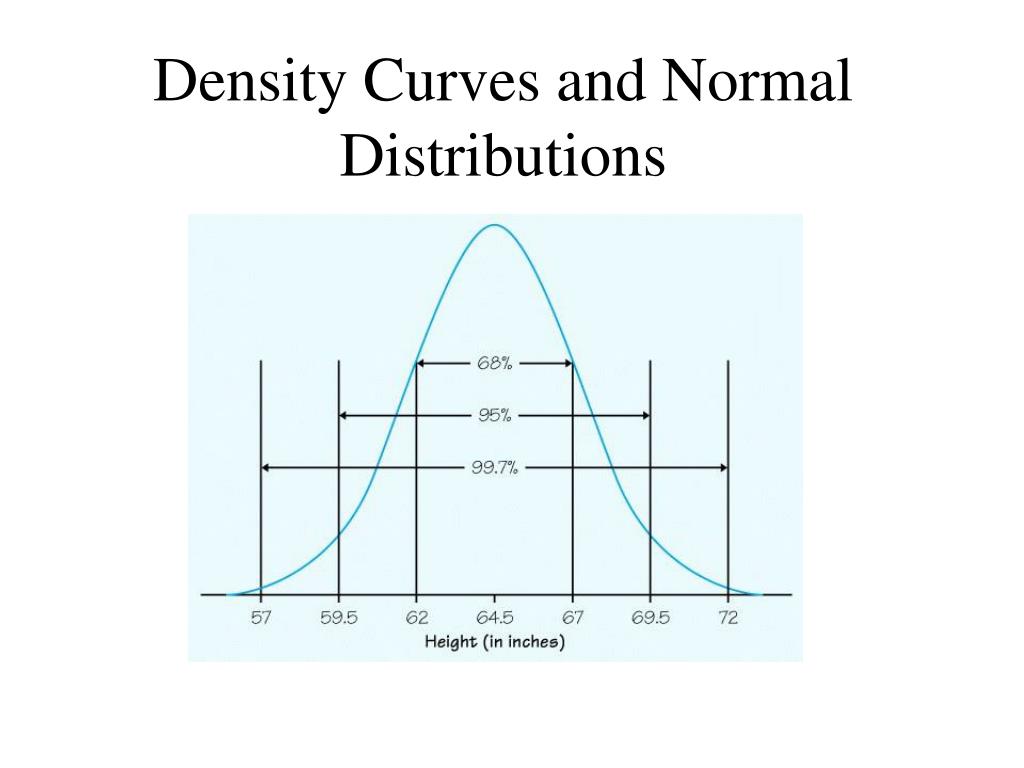
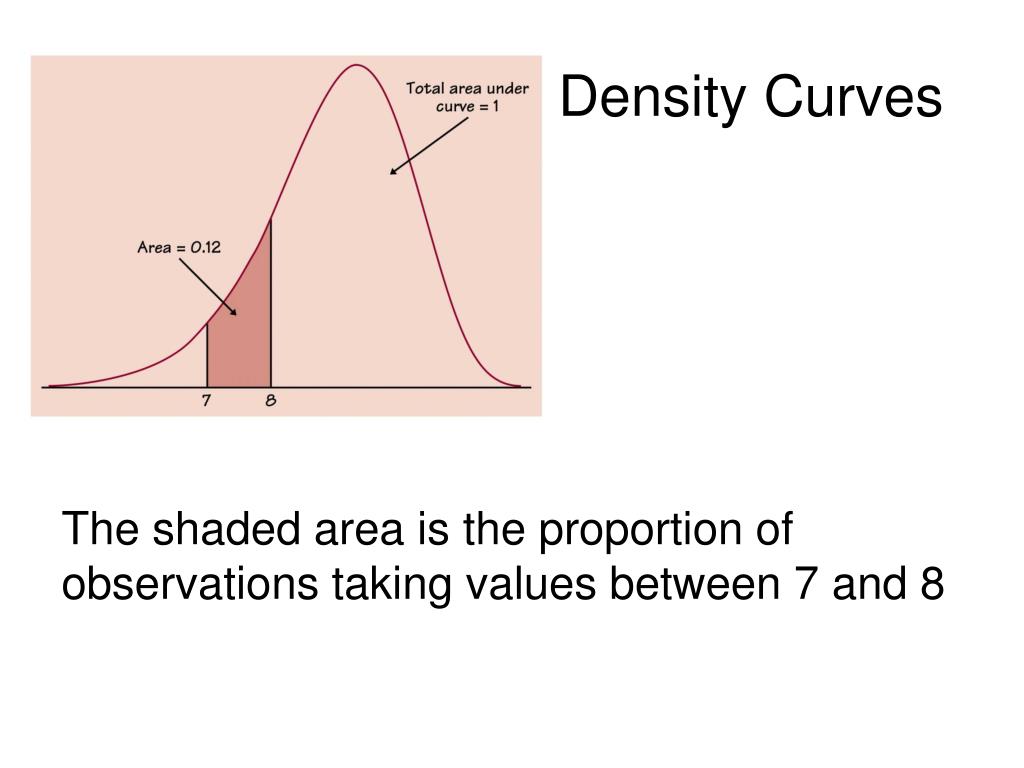
Important Fact: The total area under a density curve is always equal to 1. Always! This represents 100% of your data. Think of it like a giant pie, where the curve slices up the pie into probabilities. Pretty neat, huh?
Why Should I Care About the Height?
Alright, so why bother figuring out the height of this curve? Well, the height at a particular point tells you the relative likelihood of observing that value. It's not a direct probability (remember, probabilities are tied to the area under the curve!), but it's proportional to it.
Think of it like this: if the curve is really tall at a certain point, it means that values around that point are much more common in your dataset. If it's short, those values are less frequent.
Knowing the height helps you compare different values and understand the shape of your data. Plus, it's just a cool thing to know! Imagine dropping that knowledge at your next party. You'll be the life of the statistical get-together!

The Quest for the Height: Methods Unveiled!
So, how do we actually find this elusive height? There are a few different ways, depending on what kind of density curve we're talking about.
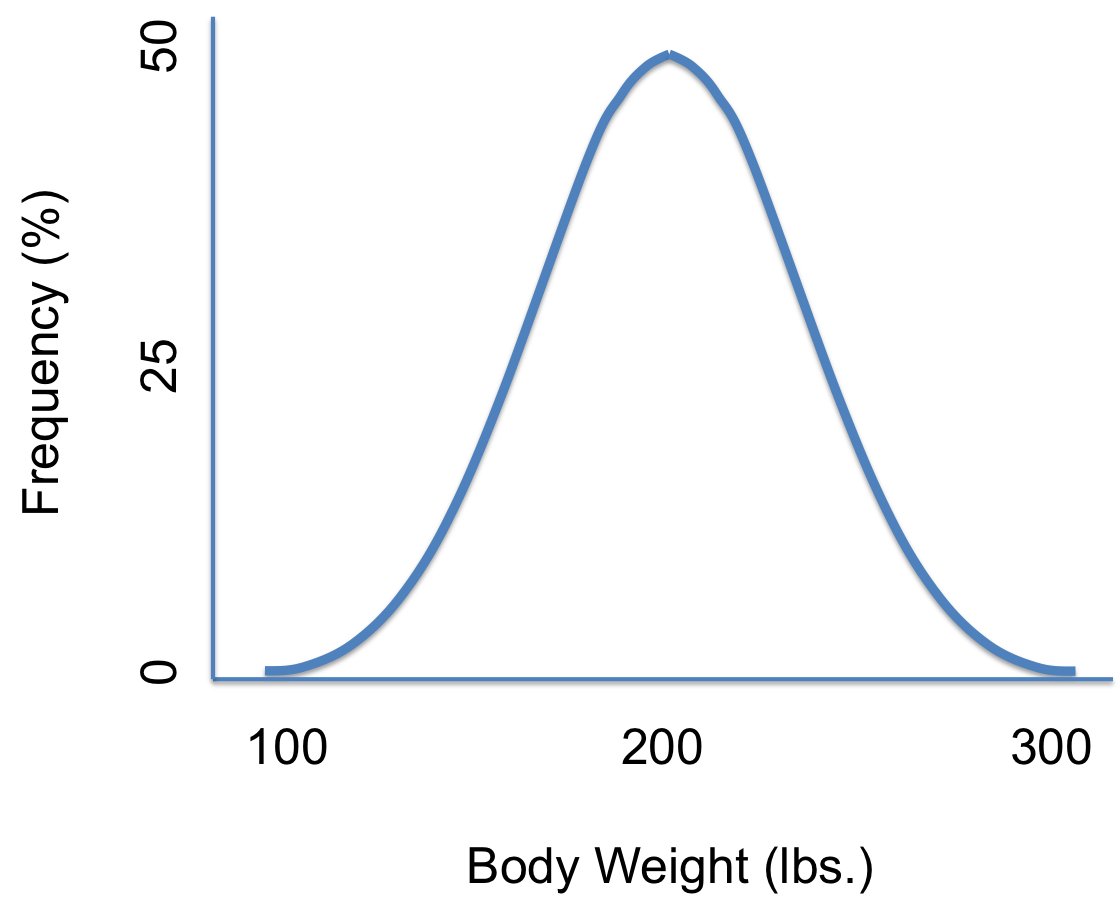
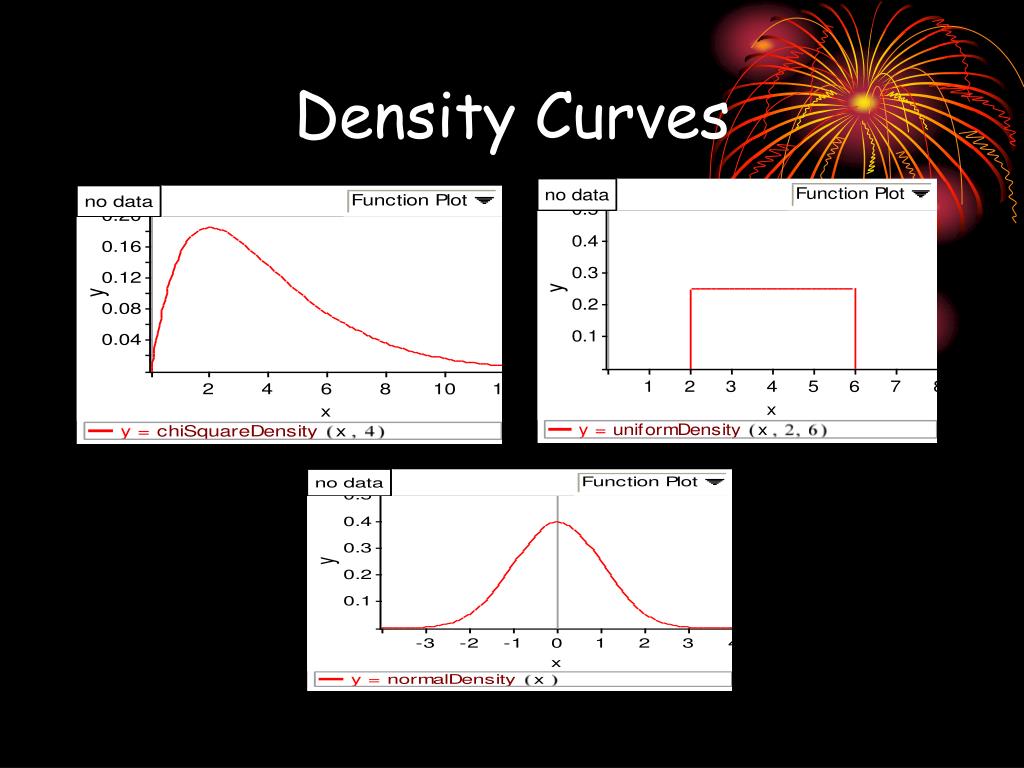
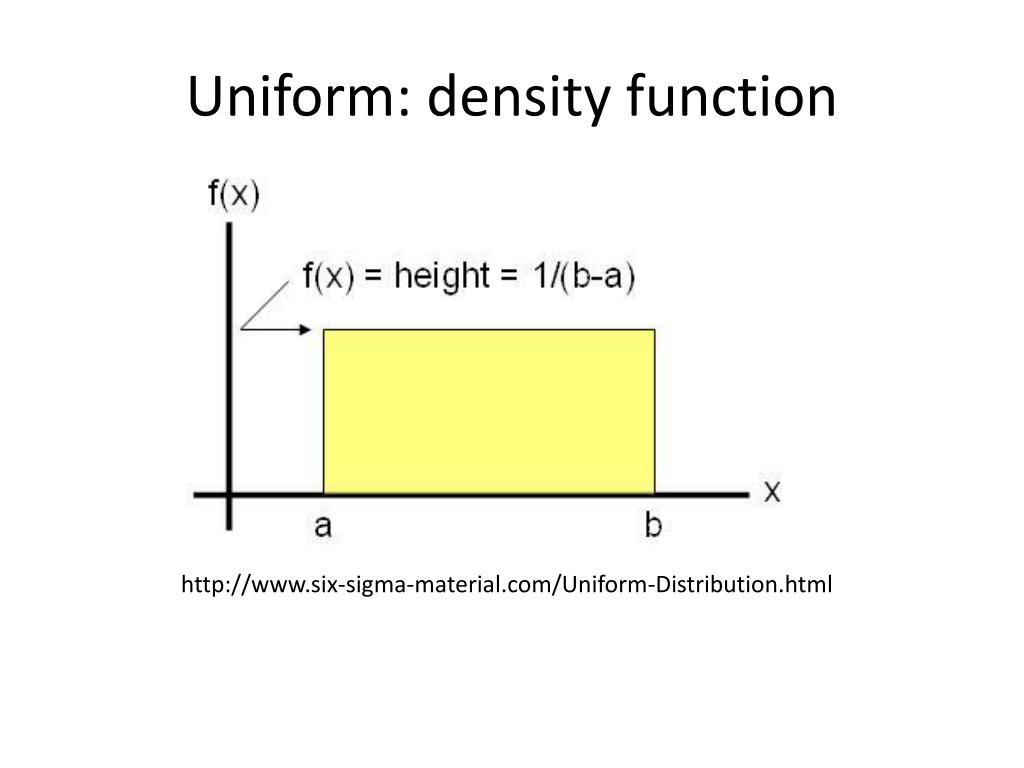
1. For the Normal Distribution (aka the Bell Curve):
Ah, the bell curve! Everyone's favorite (or least favorite, depending on your exam scores!). The normal distribution has a specific formula that makes finding its height relatively straightforward. The formula looks like this (brace yourself, it's a bit mathy!):
f(x) = (1 / (σ * sqrt(2π))) * e^(-((x - μ)^2) / (2σ^2))
Okay, let's break that down, so it doesn't look so scary:
- f(x): This is the height of the curve at a particular value of x. That's what we're trying to find!
- x: The value you're interested in. For example, if you're looking at heights, 'x' might be 5'10".
- μ (mu): This is the mean (average) of your data.
- σ (sigma): This is the standard deviation, which tells you how spread out your data is.
- π (pi): Good ol' pi, approximately 3.14159.
- e: Euler's number, approximately 2.71828. It's a mathematical constant that pops up everywhere.
So, to find the height at a specific 'x' value, you just plug in the mean, standard deviation, 'x', and let your calculator do the rest! Don't worry, most statistical software packages and online calculators will do this for you automatically. You don't have to memorize that formula (unless you really want to impress someone!).

Fun Fact: The very peak of the normal distribution (right at the mean) has the highest density. Its height is (1 / (σ * sqrt(2π))). Less math if you only need the highest point!
2. Using Statistical Software (R, Python, etc.):
If you're dealing with more complex density curves (ones that aren't perfectly normal), statistical software is your best friend! These programs have built-in functions to estimate density curves from your data. Once you've estimated the curve, you can easily find the height at any point.
For example, in R, you might use the `density()` function to estimate the density curve. Then, you can use the `predict()` function (or simply look up the estimated density value in the `density()` output object) to find the height at a specific value of 'x'.
Python with libraries like NumPy, SciPy, and Matplotlib also offers powerful tools for density estimation and visualization. You can use functions like `gaussian_kde` from SciPy to estimate the density and then evaluate it at specific points.

Pro Tip: These software packages often generate the density curve visually, which can give you a good idea of where the peaks and valleys are before you even start calculating heights!
3. Kernel Density Estimation (KDE):
KDE is a technique used to estimate the density curve when you don't know the underlying distribution of your data. It's like building a density curve from a collection of small "bumps" (kernels) centered around each data point. The shape and width of these bumps (determined by the "bandwidth") affect the smoothness of the final curve.
The formula for KDE is a bit more involved, but the basic idea is to sum up the contributions of all the kernels at a particular point 'x'. Statistical software handles the calculations for you, so you don't have to worry about the nitty-gritty details.
Quirky Detail: The choice of bandwidth in KDE is crucial! A small bandwidth can lead to a spiky, over-fitted curve that reflects the noise in your data. A large bandwidth can lead to an overly smooth, under-fitted curve that hides important features.
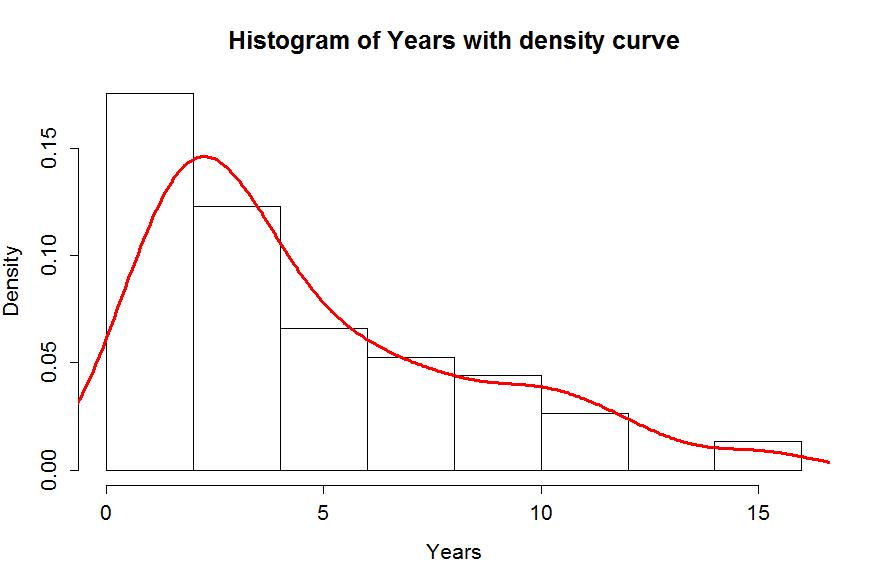
4. Approximation from Histograms:
If you only have a histogram (a bar chart representing the frequency of data in different intervals), you can approximate the height of the density curve. Draw a smooth curve that connects the midpoints of the tops of the bars. The height of this curve at any point is an approximation of the density.
Warning: This is a rough estimate! It works best when you have a lot of data and the histogram has many narrow bars.
A Word of Caution: It's All Relative!
Remember, the height of the density curve isn't a probability itself. It's a relative measure of likelihood. To find probabilities, you need to calculate the area under the curve over a specific range of values.
Imagine two different density curves. One is tall and skinny, the other is short and wide. The tall curve might have a higher height at its peak, but the area under both curves is still 1. So, the relative likelihood is higher for values near the peak of the tall curve, but the overall probability of observing a value in a certain range depends on the area.
Wrapping Up: Embrace the Curve!
Finding the height of a density curve might seem like a small detail, but it's a key part of understanding your data. It helps you visualize distributions, compare values, and make informed decisions.
So, go forth and explore the fascinating world of density curves! Don't be afraid to experiment with different methods and software packages. And remember, even if the math seems intimidating, the underlying concepts are surprisingly intuitive. Happy analyzing!