How To Add Header Column To Hive Table Csv

Hey there, data enthusiast! Ever stared at a Hive table populated from a CSV file, squinting and wishing those darn columns had proper headers? Yeah, me too. It's like trying to understand a joke whispered in a crowded room – frustrating, right? But fear not! Today, we're going on a little adventure to conquer this common data woe and make your Hive life so much easier. Get ready to transform that confusing jumble of columns into a beautifully organized, self-documenting masterpiece. Trust me, it's way less scary than it sounds!
Think of it this way: without column headers, you're basically navigating a map without street names. Sure, you might eventually figure out where you are, but wouldn't it be nice to know instantly? Column headers are the street names of your data, and adding them to your Hive table from a CSV is like giving your analysis a GPS. Ready to upgrade your data navigation skills? Let's dive in!
Why Bother with Headers Anyway?
Okay, okay, I hear you. "But why is this so important?" you ask. Valid question! Let's break down the benefits of having proper column headers in your Hive table:
Must Read
- Readability: This is the big one! Instead of guessing what `col_1`, `col_2`, and `col_3` mean, you get descriptive names like `customer_id`, `order_date`, and `total_amount`. It's like the difference between reading a novel and trying to decipher hieroglyphics. Which sounds more appealing?
- Maintainability: Imagine you're writing a complex Hive query. Without headers, you'll be constantly referring back to the CSV file to remember which column is which. With headers, your queries become self-documenting, making them easier to understand and maintain (especially when you revisit them months later... because let's be honest, we've all been there!).
- Collaboration: Data analysis is rarely a solo act. With clear headers, your colleagues can understand your data and queries instantly, fostering better collaboration and reducing confusion. Think of it as speaking the same language – much more effective than grunting and pointing!
- Data Discovery: When exploring your data, proper headers make it easy to identify the key variables and their relationships. It's like having a treasure map that clearly labels all the landmarks. "X marks the spot for customer insights!"
See? Headers aren't just a cosmetic improvement; they're a fundamental building block for effective data analysis. And they're not as hard to implement as you might think!
The (Slightly) Tricky Part: The CSV Itself
Before we even touch Hive, let's address the elephant in the room: the CSV file. Does it already have headers? If so, awesome! You're halfway there. If not, don't panic. We have options!
Scenario 1: CSV Already Has Headers
Hallelujah! This is the easiest case. When creating your Hive table, you simply need to tell Hive to skip the header row during the import process. We'll get to the specifics of how to do this with code snippets shortly. Basically, you're saying, "Hey Hive, ignore the first line, that's just for us humans to read." Simple, right?
Scenario 2: CSV Does NOT Have Headers
Okay, slightly more work, but nothing insurmountable. Here are a couple of strategies you can use:
- Option A: Edit the CSV Directly: Open the CSV file in a spreadsheet program (like Excel, Google Sheets, or LibreOffice Calc) and add a row at the top with your desired column names. Save the file. Voila! Your CSV now has headers. This is often the quickest and easiest approach, especially for smaller files. Just be mindful of the encoding! UTF-8 is generally your friend.
- Option B: Use a Script (e.g., Python): If you're dealing with a massive CSV file that's too unwieldy to open in a spreadsheet, or if you need to automate the process, you can use a script (like Python) to add the header row. This might sound intimidating, but it's a valuable skill to have in your data toolbox.
For the sake of keeping things simple and focusing on Hive, let's assume you've either already verified your CSV file has headers or you have added them.
Adding Headers in Hive: The Code!
Alright, time for the fun part! Let's get our hands dirty with some Hive code. Remember to adjust the paths and table names to match your specific environment.
The Magic Words: `TBLPROPERTIES`
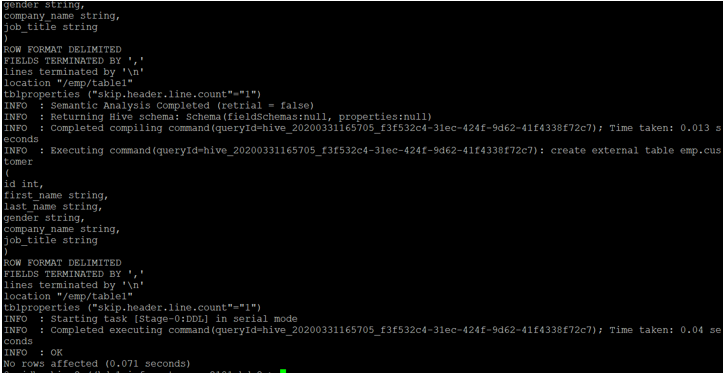
The key to telling Hive to skip the header row lies in the `TBLPROPERTIES` clause when you create your table. Specifically, we'll use the `skip.header.line.count` property.
Here's how it works:

Let's assume you have a CSV file named `data.csv` stored in HDFS at the location `/user/hive/warehouse/data/` and it does have header. You want to create a Hive table named `my_table` with columns reflecting the data in your CSV.
CREATE TABLE my_table (
column1 STRING,
column2 INT,
column3 DOUBLE
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/user/hive/warehouse/data/'
TBLPROPERTIES ("skip.header.line.count"="1");
Explanation:
- `CREATE TABLE my_table (...)`: This defines the structure of your table. Make sure the data types of your columns (`STRING`, `INT`, `DOUBLE`) match the data in your CSV file. Double-check these! A mismatch will lead to errors.
- `ROW FORMAT DELIMITED FIELDS TERMINATED BY ','`: This tells Hive that your data is in CSV format (comma-separated values). If your CSV uses a different delimiter (e.g., a semicolon), adjust this accordingly.
- `STORED AS TEXTFILE`: Specifies that the data is stored as a text file.
- `LOCATION '/user/hive/warehouse/data/'`: Points Hive to the directory in HDFS where your CSV file is located.
- `TBLPROPERTIES ("skip.header.line.count"="1")`: This is the crucial part! This tells Hive to skip the first line of the file (the header row) when loading the data. If you had two header rows for some strange reason, you would use `"skip.header.line.count"="2"`.
Important Note: The `TBLPROPERTIES` are case-sensitive in some Hive configurations. So, always double check the required case for your specific Hive version.
What If I Already Created the Table WITHOUT Skipping the Header?
Oops! Don't worry, it happens. No need to recreate the entire table. You can alter the table properties to add the `skip.header.line.count` property using the `ALTER TABLE` command:

ALTER TABLE my_table SET TBLPROPERTIES ("skip.header.line.count"="1");
After running this, Hive will skip the header line when you query the table. Neat, huh?
Verification: Does It Work?
The moment of truth! After creating or altering the table, run a simple query to see if the headers are being skipped correctly:
SELECT * FROM my_table LIMIT 5;
If you see the actual data and not the header row in the results, congratulations! You've successfully added headers to your Hive table from a CSV file. Give yourself a pat on the back! If you're seeing the header row, carefully review your `CREATE TABLE` or `ALTER TABLE` statement and make sure the `TBLPROPERTIES` are set correctly and that the table points to the correct file path.
Advanced Tips and Tricks
Okay, now that you've mastered the basics, let's sprinkle in a few more advanced techniques to really level up your Hive game:

- Using SerDe for Complex CSV Formats: If your CSV file has more complex formatting (e.g., quoted fields, different escape characters), you might need to use a custom SerDe (Serializer/Deserializer). A common choice is the `OpenCSVSerde`. This gives you more control over how Hive parses the CSV file. Exploring SerDes is a topic for another deep dive, but keep it in mind if you encounter particularly challenging CSV files.
- Partitioning for Performance: If your table contains large amounts of data, consider partitioning it based on a relevant column (e.g., date, region). This can significantly improve query performance.
- External Tables vs. Managed Tables: We created an external table, which means Hive doesn't own the underlying data file. If you drop an external table, the data file remains untouched. In contrast, if you drop a managed table, Hive also deletes the underlying data file. Choose the type of table that best suits your data management needs.
These are more advanced topics, but they can significantly impact the performance and scalability of your Hive queries. Keep them in mind as your data analysis skills evolve.
Wrapping Up and Looking Ahead
You did it! You've successfully learned how to add header columns to your Hive table from a CSV file. Now you can kiss those confusing `col_1`, `col_2`, and `col_n` columns goodbye and embrace the clarity and efficiency of properly labeled data. I told you it wasn’t so bad!
But this is just the beginning! The world of Hive and data analysis is vast and exciting. There are so many more things to learn and explore, from optimizing your queries to building complex data pipelines. Don't be afraid to experiment, try new things, and most importantly, have fun! Data is all around us, waiting to be discovered and analyzed. Go forth and unlock its secrets!
Remember that every expert was once a beginner. Keep practicing, keep learning, and keep exploring the fascinating world of data. Your journey has just begun, and the possibilities are endless. Now go on, you data rockstar, and make some magic happen!